Case study
Healthcare
Custom Telemedicine Solution
Published: 6 July, 2022 · 10 mins read
Software developers may encounter performance limitations of Entity Framework, especially when dealing with large databases. These include slow query execution times and inefficient database operations. We have gathered several practical strategies to enhance Entity Framework performance, including query optimization, batching, raw SQL queries, caching strategies, and indexing databases.
Databases grow alongside our clients’ business. But since the load of systems increases over
time, it could cause the entity framework slow performance. Another reason for the
performance degradation is a change in business rules.
SSD manufacturers are constantly inventing new technologies, and Microsoft offers memory-optimized
tables since version 2014. However, speeding up drives and increasing memory size doesn’t always
solve the issues. In most cases, the Entity Framework core performance can be speeded up dramatically using
caching of query
results. But considering the most popular OLTP scenarios, a big obstacle is the lack
of correct and accurate cache invalidation.
Although high-level cache invalidation for MS SQL server with the help of SqlDependency has already
been presented, this technology has not become widespread due to numerous limitations.
Having been involved in solving performance issues caused by both reasons – growing
databases and growing complexity of queries according to changes in business rules, I want
to share some insights in this field. They should help you improve entity framework
performance by many times.
So, let’s take as an example of a pretty simplified database structure and explore the way that
can help us solve entity framework performance issues.
Importantly, not to weaken the performance, you need to have a proper understanding of the client’s
business. Also, access to the profiling and monitoring of the production systems would be mandatory.
Before we get to the entity framework performance improvements and DB structure, let’s look
at the system. First of all, we need to consider staff turnover. This index is usually the
same for the entire industry. For instance, when it comes to the retail industry, turnover
might be about 1% a day. It means that the client/organization with 1,000 employees on the
payroll usually hires and fires 10 people a day.
So, the tables on the diagram below change just 20 times a day for the organization above. For
this reason, a cached query result should be refreshed from DB just 20 times a day. It is a great
opportunity for us to implement invalidation of cache. The diagram is pretty simplified and contains
only navigational and reverse properties required for reading comprehension of the query below.
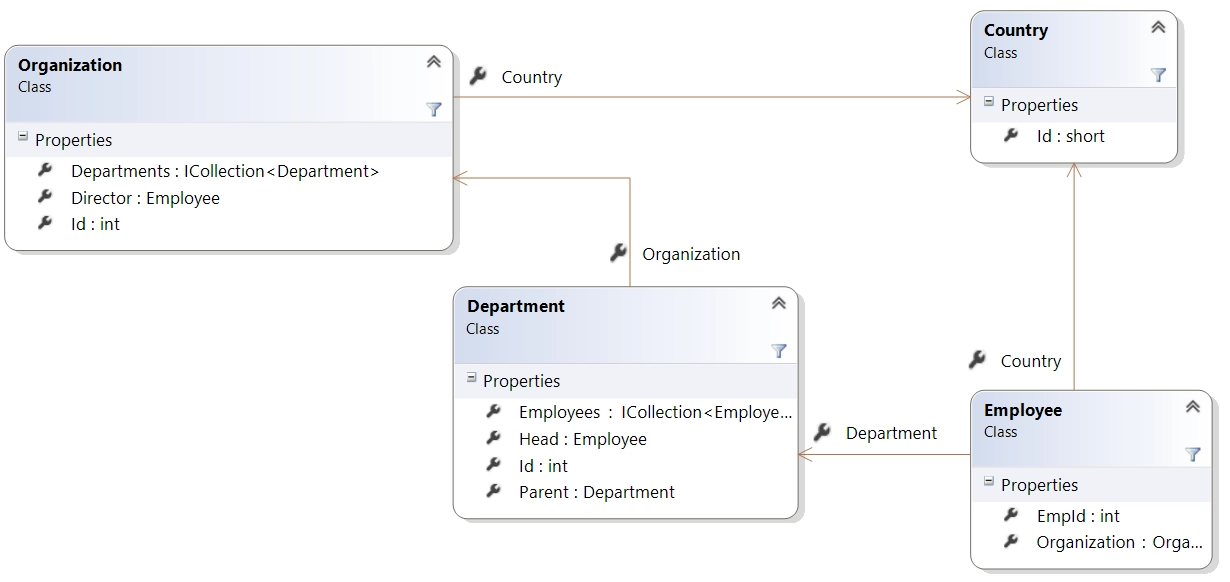
On one hand, a stream of updates is usually significant just on a few tables. On the other
hand, a bulk of tables/sets is often queried on each operation.
Before we move further, let me tell a little bit more about analysis in a vacuum. The invalidation
of countries is much easier than the invalidation of staff – the countries are usually configured
during the launch of a production system and rarely updated afterward. The four tables on the
diagram above will be referenced by all the subsystems that are outside of the scope today:
So, let’s write a query that will be accelerated up to 10x:
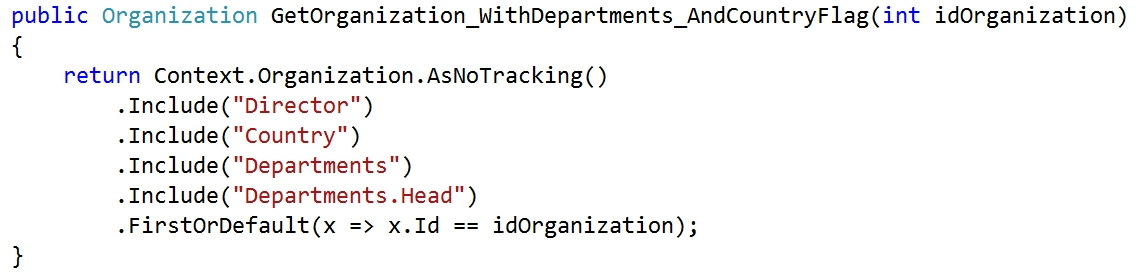
This query returns a structure of departments of a specified organization. The result includes a director (navigation property “Director”) of the organization and heads of departments (navigation property “Department.Head”).
First of all, let’s look at the conditions when the cache of the query above follows
accurate and correct invalidation. It is enough to flush cached query results in three cases – if an employee, a department, or an organization has been updated during some Entity Framework SaveChanges() call.
Obviously, we can not control all of the SaveChanges, so we need to intercept each SaveChanges()
call and do our logic in ObjectContext.SavingChanges event handler. All we need is to mark corresponding
OrganizationId properties with a custom attribute, CacheInvalidation. For example:
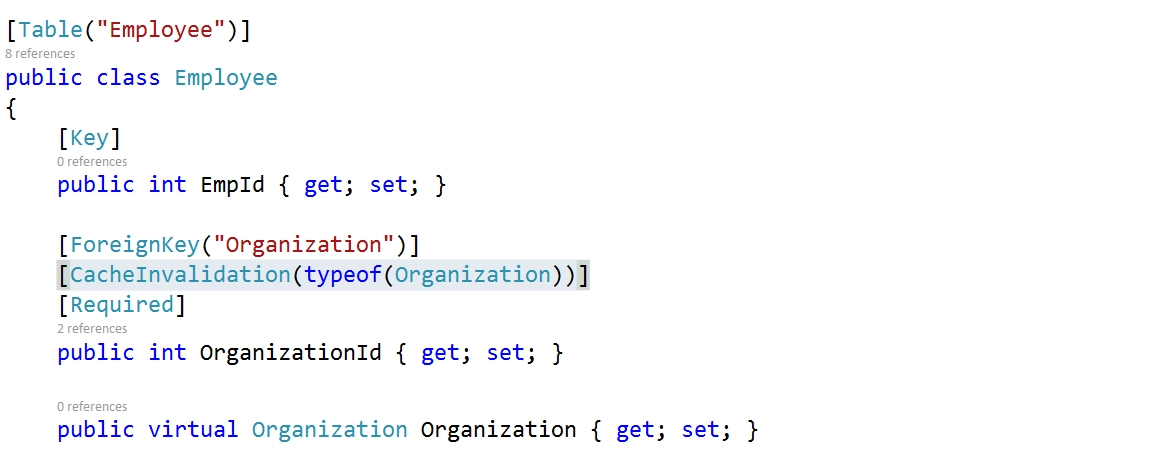
By the way, a CacheInvalidation attribute is also suitable for database-first behavior. In
this case, the attribute should target the entity class. Besides, optional Property should
specify which property refers to an entity id.
In the same way, we will mark the OrganizationId and Id properties of the Department and Organization
classes. That’s it. With the help of this metadata, Entity Framework will flush up to two cached
query results. Why two? Because we have to flush both the original organization’s info and the
current one to improve entity framework performance.
Flushing queries cache according to the country changes is easier. As we don’t have queries with
the id of a country as a parameter, we will invalidate all the cached query results on each update
of every country entity. It is not a problem since such changes are expected to occur very rarely.

So, we have already implemented and configured correct and accurate invalidation for entity
framework performance tuning. It is a transparent process – we do not need to modify both
written and not written yet calls to SaveChanges().
Here is the updated query with Entity Framework caching. All we need is to wrap our query into DependenciesExtentions.LazyLoad:
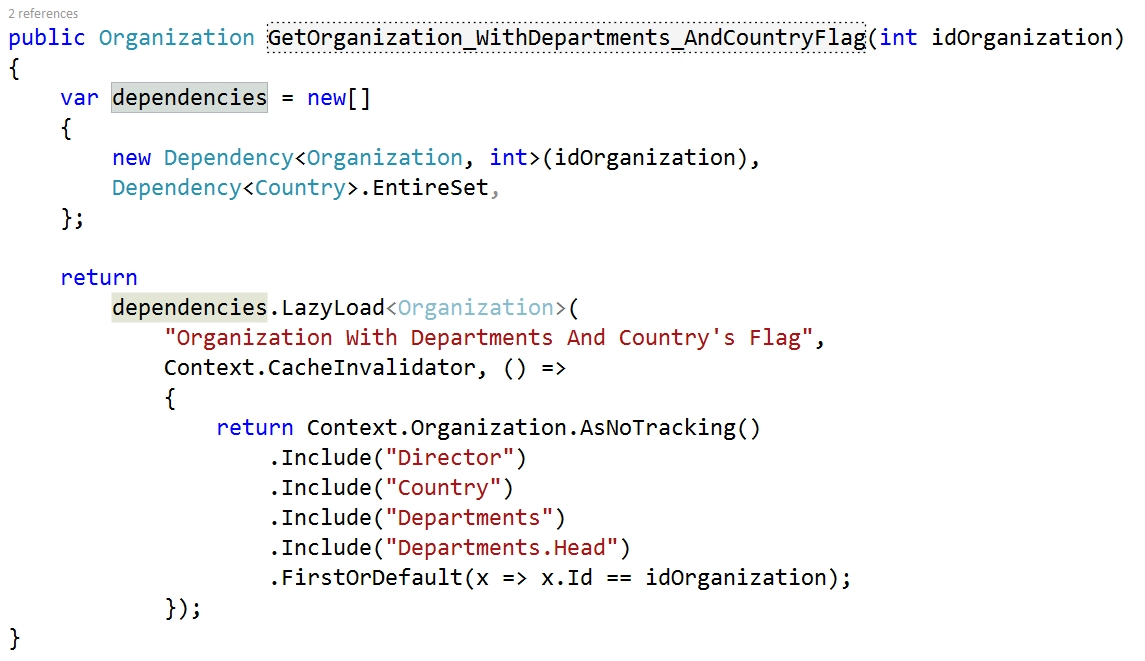
Here are two important aspects of this method. First, the dependencies variable declares
invalidation criteria – whose timestamps should be equal to valid cached results. Second,
the old method body was just moved to lambda.
Eventually, we added 4 instances of the CacheInvalidation attribute to our code-first model.
Besides, we have wrapped our query into a dependencies extension method called LazyLoad. In addition,
we have made decisions on invalidation strategy based on the analysis. Finally, we have injected
CacheInvalidator into our DbContext class. That is it.
This solution also includes drawback measurements as well as performance gain measurements.
By the way, the CacheInvalidation library is open-source, MIT licensed public git repo.
Here is a link to the bitbucket repo.
To make the internals of CacheInvalidation.EF library is easier to understand, take a look at
the flow diagram “How does cache invalidation work”. It shows interactions of two apps with the
SQL Server DB, the Invalidation Storage, and the Cache.
Diagram illustrates four cases:
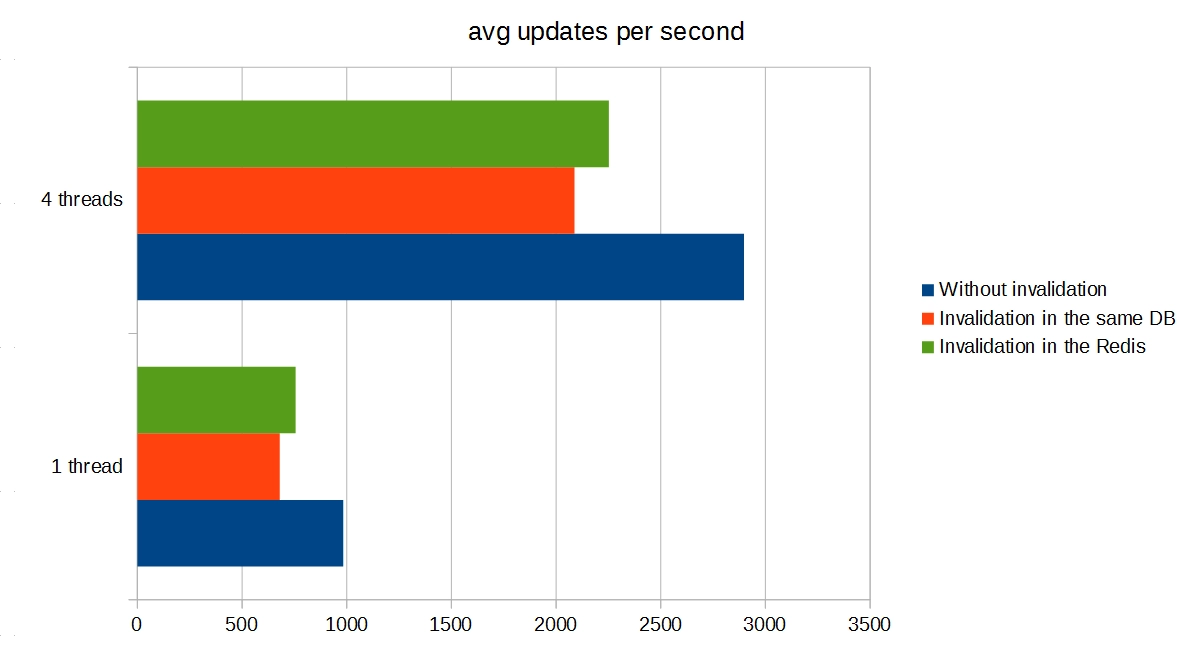
In this article, we have discussed an Entity Framework performance best practices that resolve the problem
of correct and accurate invalidation of cached query results in a distributed environment. Other areas, including Entity Framework performance issues (relatively slow processing of SaveChanges() and long initialization of Entity Framework on the first query), are out of scope.
However, the principles of cache invalidation and entity framework performance tips used here
are suitable for any ORM, not just Entity Framework. When using Entity Framework, the implementation
of those principles becomes almost transparent. Hope this will help you improve the performance
of the entity framework and make it much faster.
